Best Practices for Multi-Region Deployments in AWS AppStream 2.0 and AWS WorkSpaces
The AWS outage on October 20, 2025, in the US-EAST-1 Region disrupted multiple services, impacting organizations relying on single-region deployments. For End-User Computing (EUC) environments, such disruptions can halt remote work and application access, underscoring the need for resilient architectures.
The following whitepaper from Samana Group outlines best practices for deploying AWS AppStream 2.0 and AWS WorkSpaces across multiple AWS Regions to ensure continuity during regional outages. By leveraging multi-region strategies, automated failover, and robust data replication, organizations can achieve their expected Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO), maintaining business operations.
Introduction
AWS AppStream 2.0 provides on-demand application streaming, while AWS WorkSpaces delivers persistent and non-persistent virtual desktops, both critical for hybrid workforces. The October 20, 2025, outage in US-EAST-1, a key region for many deployments, disrupted services due to underlying infrastructure issues, affecting global operations. AWS’s global infrastructure, with over 30 Regions and 100 Availability Zones (AZs), offers fault isolation, but single-region EUC setups expose businesses to the vulnerability of regional failures. This whitepaper details how to design resilient EUC environments using active/passive or standby configurations, ensuring availability during outages.
Understanding Resilience in AWS EUC
AWS EUC resilience leverages the isolation of AWS Regions and AZs. Regions are geographically separate, and AZs provide intra-region redundancy. A regional outage, like the one that just occurred, impacts all AZs in that Region, necessitating cross-region failover. Key resilience goals include:
- Availability Zones (AZs): Distribute workloads across multiple AZs for intra-region fault tolerance.
- Regions: Use multiple Regions for inter-region redundancy, with primary (active) and secondary (standby) setups.
- RTO/RPO: Target RTO under 30 minutes for failover and an RPO target in compliance with your business’s needs via continuous replication.
- Data Plane vs. Control Plane: Prioritize data plane operations (e.g., user access) over control plane (e.g., provisioning APIs) for faster recovery.

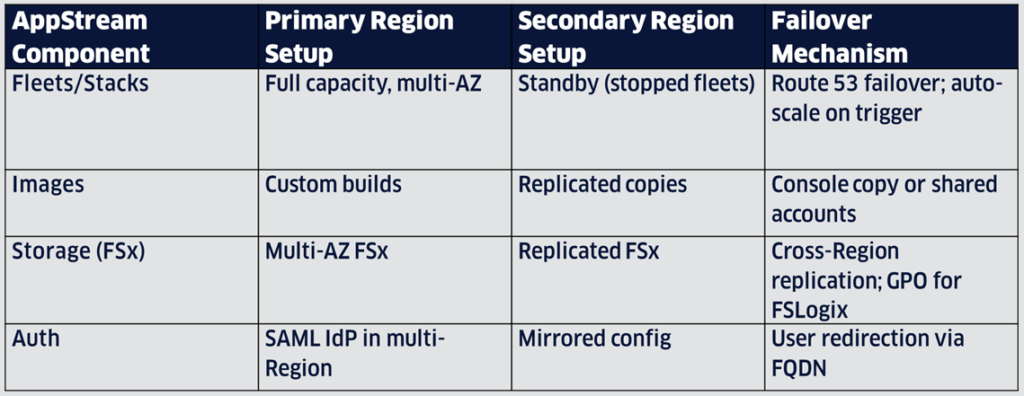
Best Practices for AWS AppStream 2.0 Resilience
AWS AppStream 2.0 streams applications from the cloud, requiring resilient fleet management and user data persistence. A pilot light or warm standby strategy (maintaining minimal capacity in a secondary Region that scales on demand) ensures faster recovery during outages.
1. Multi-Region Deployment Architecture
Deploy identical fleets and stacks in primary (e.g., eu-west-1) and secondary (e.g., eu-west-2) Regions. Use AWS Transit Gateway or VPC peering for connectivity, ensuring subnets support port 445 for Amazon FSx file shares.
- Image Replication: Copy custom AppStream images to the secondary Region via the AppStream console or by using an automated script to avoid manual tasks. Enable multi-Region deployment for AWS Managed Microsoft AD.
- Authentication: Use SAML-based identity providers (e.g., Okta) for seamless user redirection; avoid single-Region IAM Identity Center dependencies.
- Capacity Planning: Request service quota increases in the disaster recovery (DR) Region (up to 60 instances/minute across accounts). Provision fleets at 20 instances/minute to handle failover scaling.
2. Data Persistence and Replication
- User State: Use Amazon FSx for Windows File Server with multi-AZ and as a strategy for multi-Region replication for home folders and profiles (via FSLogix). Avoid native S3 persistence to reduce latency and ensure consistency.
- Networking: Allocate VPC CIDR blocks conservatively (/16 max) and use multiple subnets per AZ to prevent IP exhaustion during fleet scaling.
3. Failover and Monitoring
- DNS Failover: Configure Amazon Route 53 with health checks on fleet endpoints to redirect traffic automatically during outages.
- Automation: Use AWS Lambda and Amazon EventBridge to scale fleets in the secondary Region upon outage detection.
- Monitoring: Monitor fleet health with Amazon CloudWatch, setting alarms for provisioning failures or latency spikes.
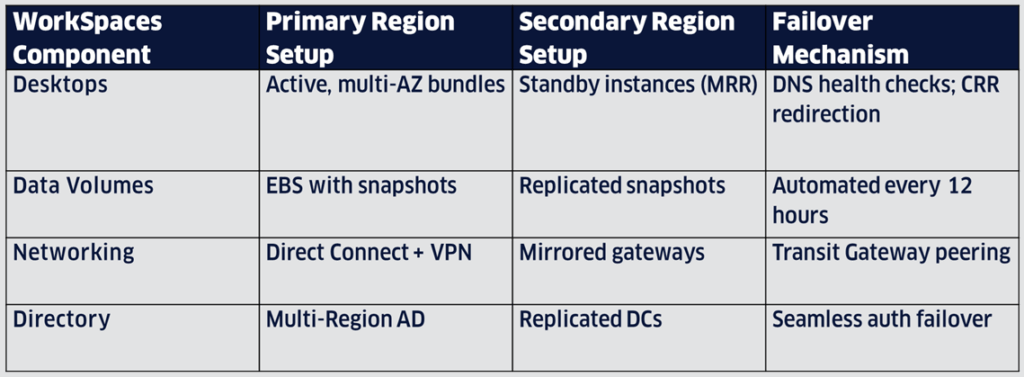
Best Practices for AWS WorkSpaces Resilience
AWS WorkSpaces provides both persistent and non-persistent virtual desktops, ideal for knowledge workers. Multi-Region Resilience (MRR) enables automated standby provisioning in secondary Regions, targeting RTO under 30 minutes.
1. Multi-Region Resilience Configuration
Enable MRR for Personal WorkSpaces (Windows/BYOL only; excludes GPU bundles). Use a Fully Qualified Domain Name (FQDN) as the registration code for DNS-based redirection.
- Standby WorkSpaces: Automatically provision standby instances in the secondary Region (e.g., us-east-1 primary, us-west-2 secondary). Use CLI scripts to ensure snapshots occur every 12 hours to help ensure RPO under 12 hours.
- Supported Regions: Pair Regions with low latency for optimal performance.
2. Data and Network Resilience:
- Volume Replication: Enable one-way replication for system and user volumes; back up changes to external drives post-failover.
- Networking: Use redundant Direct Connect or IPSec VPN failover, connected via Transit Gateway for hybrid environments.
- Directory Services: Replicate AWS Managed Microsoft AD across Regions; avoid Simple AD due to replication limitations. (Note: Since not all customers use AWS Managed AD, one can also deploy separate directories in the secondary Region without replication. This approach can be considered as an alternative, provided a clear DR plan exists to pre-create and maintain services that lack native replication, ensuring readiness during failover.)
3. Failover Automation and Testing:
- Cross-Region Redirection (CRR): Use Route 53 failover policies to redirect users during primary Region failures.
- Failback: A well-documented failback process should be in place to prevent duplication and data loss. Perform manual failback post-outage, waiting 15-30 minutes after switching.
- Observability: Monitor latency with CloudWatch and AWS X-Ray; conduct quarterly failover simulations.
Cross-Service Resilience Strategies
Networking and Connectivity
- Hybrid Resilience: Deploy redundant connections (e.g., dual Direct Connect to separate AWS points-of-presence).
- Global DNS: Use Route 53 for weighted routing and health checks to balance traffic across Regions.
Security and Compliance
- Identity: Federate with external IdPs (e.g., Okta) in multi-Region setups; use regional STS endpoints for secure authentication.
- Encryption: Enable at-rest and in-transit encryption; replicate keys using AWS KMS multi-Region keys.
Monitoring and Automation
- Chaos Engineering: Simulate outages with AWS Fault Injection Simulator to validate resilience.
- Runbooks: Automate recovery with AWS Systems Manager; test runbooks quarterly to ensure reliability.
Implementation Roadmap
- Assess (1-2 Weeks): Inventory dependencies and model outage impacts using AWS Resilience Hub.
- Design (2-4 Weeks): Select paired Regions and architect primary/secondary setups.
- Build (4-6 Weeks): Deploy replicated resources and configure failover mechanisms.
- Test (Ongoing): Conduct failover drills and measure RTO/RPO performance.
- Optimize: Use AWS Cost Explorer to monitor costs and refine configurations based on metrics.
Conclusion
The 2025 AWS outage highlights the critical need for multi-region architectures in EUC environments. By implementing AppStream 2.0 and WorkSpaces with multi-Region resilience, organizations can mitigate regional disruptions, ensuring seamless access for users. Strategies like MRR, Route 53 failover, and replicated storage enable rapid recovery, while regular testing and automation enhance reliability. Building resilience is an ongoing process, requiring continuous refinement to adapt to evolving cloud challenges.
If you would like support with this or any other strategic EUC initiatives, please DM us or email us at solutions@samanagroup.com.
References
- AWS, “Amazon AppStream 2.0 Documentation: Multi-Region Architectures.”
- AWS, “Amazon WorkSpaces Multi-Region Resilience.”
- AWS, “AWS Well-Architected Framework: Reliability Pillar.”
- AWS, “Amazon FSx for Windows File Server: Multi-Region Replication.”
- AWS, “Amazon Route 53: Configuring DNS Failover.”
- AWS, “Transit Gateway: Cross-Region Peering.”
- AWS, “AWS Managed Microsoft AD: Multi-Region Replication.”
- AWS, “Best Practices for Disaster Recovery with AWS EUC Services.”
- AWS, “AWS Fault Injection Simulator: Simulating Regional Failures.”
- AWS, “How to Replicate Amazon FSX File Server Data Across AWS Regions”
 Download our whitepaper!
Download our whitepaper!